





Listen to this blog
Many organizations are collecting and storing sensitive data about their customers which is why it is extremely important to protect and anonymize the data so it can be used easily by organizations while ensuring complete compliance with data laws and regulations. Tokenization helps organizations safeguard personal and sensitive customer data while allowing them to maintain their business utility. In this way, tokenization also protects sensitive data against any privacy breaches by hackers and helps to gain customers’ trust, especially in highly regulated industries like the financial and healthcare sectors.
What is Data Tokenization?
The process of tokenization involves replacing sensitive data elements by an alias (non-sensitive substitute) known as a “token” that can be used in a database or internal system without compromising on confidentiality. There is no essential value or meaning to the token; it is simply a randomized data string.
Even though tokens are unrelated values, they retain certain values of the original data, such as length or format, allowing them to be used in a seamless manner. Sensitive data can then safely be kept outside of an organization's internal systems.
It is particularly important to make this distinction because there is no mathematical relationship between the token and its original number. Therefore, no algorithm or key can be used to deduce the original data for a token. This makes tokens irreversible and therefore safer than encrypted numbers. Tokenization utilizes a database, called a "token vault" to record the relationship between a sensitive value and a token. Once the vault is filled with data, it is usually encrypted to protect it. This ensures that sensitive data will not be compromised even if there is a breach of a tokenized environment.
How Data Tokenization works?
In vault tokenization, we store sensitive data along with its corresponding non-sensitive data in a secure database called a ‘tokenization vault database”. It is possible to detokenize newly tokenized data using the vault database.
Step 1: Tokenization process begins the moment sensitive data is captured.
Step 2: To store data in the database, a token is generated and sent to the database. In the meantime, the actual data is stored in a vault outside the system.
Step 3: The non-sensitive data (token) is then sent back to the application.
Step 4: To retrieve the original data, the token is needed from the database and sent with the user ID to the vault via the API
Step 5: Data is decrypted and returned to the user if the vault validates the user’s access
Step 6: The authorized application now has the original data.
Data Tokenization Use Cases
Many different kinds of sensitive data are protected using tokenization, including:
⦁ Payment card data
⦁ National identifying numbers such as the Social Security number in the United States
⦁ Telephone numbers
⦁ Passport numbers
⦁ Driver’s license numbers
⦁ Email addresses
⦁ Bank account numbers
⦁ Names, addresses, birth dates
The Tokenization Process in Example
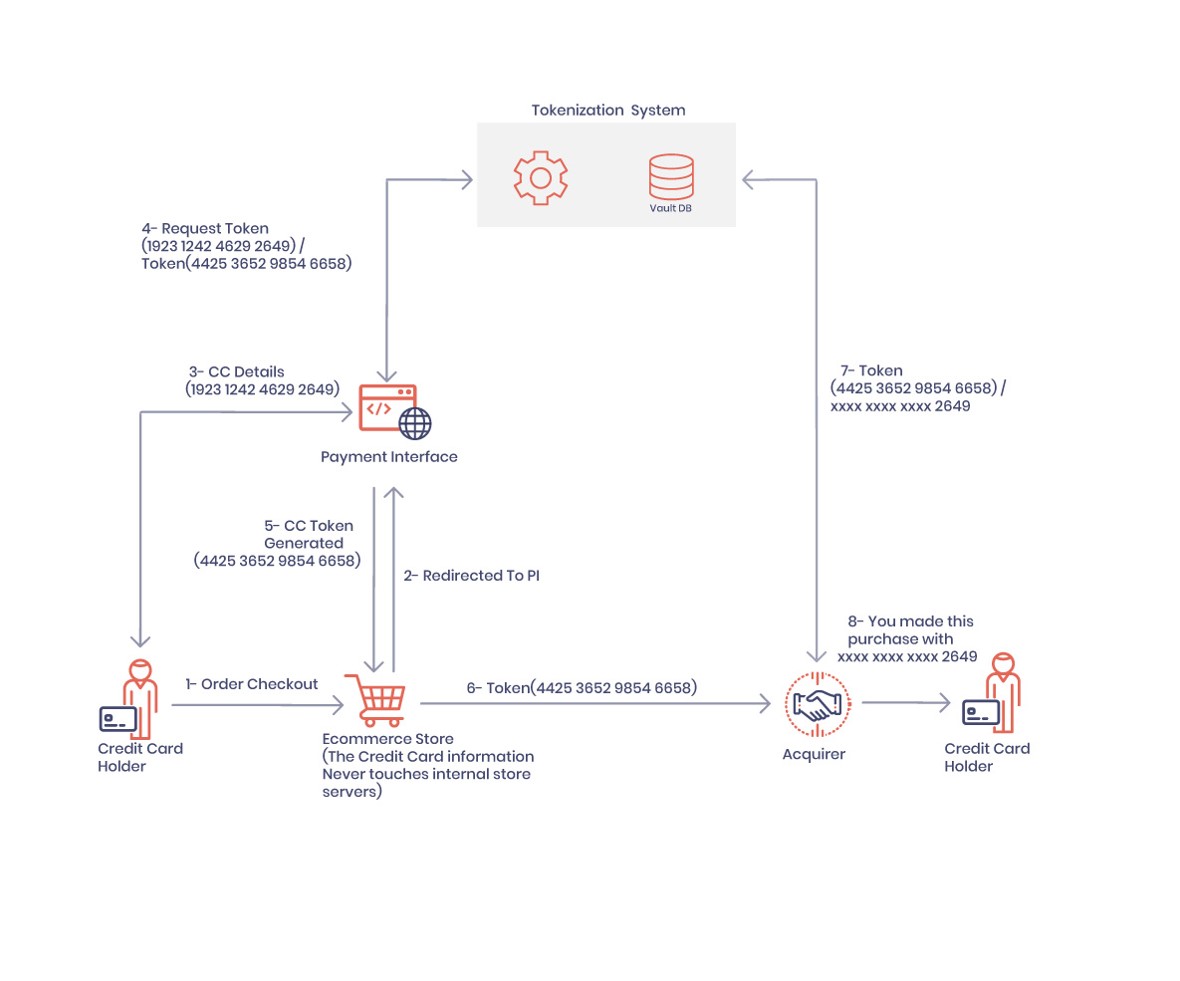
Most ecommerce stores use tokenization to capture and process credit card information in a secure and compliant manner. Tokenization adds an extra layer of security which prevents store servers from seeing sensitive card information. Customers’ card details are never disclosed in full; only basic information like the last 4 digits of your credit card, expiration date and card brand are shown. The token replaces the primary account number (PAN) with a series of randomly generated numbers. Payments are made by using these random tokens since the actual card number is stored safely in a token vault.
⦁ A customer makes a transaction and checks out with a credit card. (e.g., 1923 1242 4629 2649)
⦁ A random sequence of characters is substituted for the card number (e.g., 4425 3652 9854 6658)
⦁ In a vault, credit card and token are securely stored
⦁ In certain cases, the merchant can use the same token in multiple transactions
What are the Different Types of Tokenization Available?
Vault and vault-less tokenization are the two options available for tokenizing data.
Vault Tokenization
Vault tokenization is the older method of tokenization which involves keeping a secure database. The secure database is referred to as the tokenization vault database and is used to store sensitive information. The biggest drawback of vault tokenization is the prolonged detokenization processing time brought on by the growing database size.
As there is a need to query vault database for the corresponding token, it takes extra time to retrieve and detokenize the vaulted data. This can create delays for large databases supporting frequent queries, so companies should consider vault less tokenization if detokenization must happen at scale.
Vault-less Tokenization
In contrast to vault tokenization, vault-less tokenization uses secure cryptographic devices instead of a database to store tokens for efficiency and safety. For sensitive data conversion or token generation, secure cryptographic devices use standards-based algorithms. Detokenization can be achieved by using these tokens to generate original data.
As a result of this method, sensitive data remains encrypted throughout the payment process, potentially eliminating all cleartext cardholder data from the merchant network. Furthermore, vault-less tokenization does not require data to be replicated between data centers, thereby reducing delays.
Tokenization vs Encryption vs Masking
While Tokenization, Encryption and Masking are all cryptographic methods used for data security, there are some differences between them.
Encryption
Encryption is the process of converting plain text into information by using an algorithm into a non-readable format called ciphertext. For the information to be decrypted and returned to its original text format, an algorithm and encryption key must be used.
⦁ A small encryption key is all that is needed to decrypt data in large volumes.
⦁ used for both unstructured data including whole files and structured fields
⦁ Original data leaves the organization, but in encrypted form.
Masking
Data Masking is another effective method to protecting the privacy of data. It is a process of obscuring, anonymizing, or suppressing data by replacing sensitive data with random characters or just any non-sensitive data. As a result, disguised data can be used for tasks like software testing, account validation, user training, and sales demos without raising a company's risk profile.. There are several techniques used for data masking such as substitution, data blinding, scrambling, data shuffling or deletion.
Data anonymization or data sanitization are other terms for the process of permanently deleting all Personally Identifying Information (PII) from sensitive data.. No algorithm can recover the original data from values of masked data.
Benefits of Using Data Tokenization
Tokenization can provide several important benefits for securing sensitive customer data:
Simplified Process/ Secure Tokenization: By tokenizing data, plain-text information is replaced with an arbitrary token that is worthless if compromised. Tokenization needs just minor adjustments to current programs to add robust data protection.
Fosters Customer Trust: The use of tokenization adds an extra layer of security for websites, which increases consumer confidence.
Acts Like Real Data: By treating tokens as real data, users and applications can perform high-level analysis without being concerned about leaks. On the other hand, anonymized data offers limited analytics capabilities because you're dealing with ranges, whereas hashed and encrypted data cannot be analyzed. The right tokenization solution allows business users to share tokenized data from your data warehouse with any application without unencrypting it or exposing it inadvertently.
Reduces Risk from Data Breaches: With tokenization, organizations do not have to record sensitive information at their input terminals, store it in their databases, or transmit the data through their information systems. This protects organizations from security breaches.
Multi-Purpose Tokens: In tokenization, both single-use and multi-use tokens can be generated, such as for one-time purchases using a credit card, or when customer credit card numbers are stored to enable faster website checkout experiences in the future.
Helps in Achieving Compliance: It is easier to obtain compliance certifications (such as PCI DSS, CCPA, SOC2, GDPR, etc.) when an organization’s data environment is tokenized because it contains less material relevant to privacy regulations. However, organizations will still be responsible for and held accountable for substantial amounts of data.
How Does Tokenization Contribute to Data Security?
Organizations can leverage data tokenization to ensure that they maximize the value of their data while also keeping it secure. This puts businesses in a far better position to remain compliant with a variety of constantly changing data compliance laws and regulations, making them much less vulnerable in the case of a data breach. It’s an effective way of obtaining much-needed information such as in healthcare, financial services, and even retail, without increasing risk exposure.
In addition, data tokenization can help build customer trust by giving them peace of mind that their personally identifiable information (PII) won’t be misused. These organizations can better comply with regulations such as HIPPA, GDPR & CCPA by tokenizing both electronically protected health information (ePHI) and nonpublic personal information (NPPI).
Conclusion
Tokenization is a powerful way of dealing with sensitive data. Security and compliance alone are reasons enough to implement tokenization. In reality, online payments are difficult to secure on their own. Your business is a target for criminals if you take online payments. It is in your company’s best interest to hire experts in the field of security and tokenization, so you can save time and money in the long run.